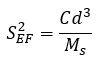Para Pierre Gy, la homogeneidad es un concepto relativo, depende de los lentes con que estemos mirando el material. Si miramos los objetos de lejos parecerán homogéneos a que si lo miramos de cerca.
La homogeneidad perfecta no existe, es una ilusión. La naturaleza es heterogénea.
Se entiende por homogeneidad de constitución cuando las diferencias entre partículas o fragmentos es nula. Es decir, todos los fragmentos son iguales en densidad, tamaño de partícula, propiedades físicas y químicas, etc. (lo que es un caso irreal).
Se entiende por homogeneidad de distribución, la distribución espacial de las partículas de tal manera que no hayan diferencias entre grupos,
A continuación, se presentan 4 diagramas que sirven para demostrar la naturaleza aleatoria de la "homogeneidad".
Caso A.- En este cuadro hay 64 componentes completamente homogéneos. Esto corresponde a la homogeneidad de constitución.
Aquí se puede apreciar que al no existir heterogeneidad de constitución, tampoco habría heterogeneidad de distribución.
Este caso no es real.
Caso B.- Módulos repetidos en la vertical y horizontal. La constitución es heterogénea, con 4 diferentes componentes, pero con la distribución estrictamente homogénea si consideramos un múltiplo del módulo 1x4 o 4x1, como por ejemplo; un rectángulo 4x3. Pero heterogénea en un cuadrado 3x3 o un rectángulo 5x2.
Un ejemplo en la vida real podría ser el de un cristal perfecto.
Caso C.- Representa una distribución completamente segregada. Los cuatro componentes están separados y forman 4 capas respectivamente homogéneas.
En la práctica, esto ilustra el peligro asociado al muestreo de agarre (grab sampling). Hay dos dimensiones de homogeneidad y 1 dimensión de heterogeneidad.
Caso D.- La figura muestra una distribución completamente aleatoria. La heterogeneidad de distribución es mínima e igual al residuo aleatorio DHL.
Equivale a seleccionar al azar, cada elemento, uno por uno, antes de ser colocado al interior del lote. Esto es equivalente a mezclar u homogenizar. Tiende a suprimir o cancelar cualquier correlación entre posición y personalidad de las unidades
Éste último constituye un ejemplo de lo más cercano que puede estar un material de la homogeneidad.
Por lo tanto, un material particulado presenta dos condiciones que provocan que el material no sea estrictamente homogéneo:
1.- heterogeneidad de constitución.- corresponde a la diferencia entre fragmentos. Ninguna partícula o fragmento es igual a otro, porque tienen distinto tamaño, distinta densidad, distinta composición física o química, etc.
2.- heterogeneidad de distribución.- corresponde a las diferencias entre grupos de fragmentos. Las partículas tienen la propiedad de agruparse y segregarse. Esta anisotropía se ve favorecida por la fuerza de gravedad que actúa en sentido vertical una vez que el material ha dejado de homogenizarse. Al ser las partículas diferentes, lo más homogéneo desde el punto de vista espacial que puede presentarse un material (Caso D), según lo expuesto en los diagramas anteriores, es que las partículas se distribuyan de manera aleatoria en el espacio. Aunque el material sea sometido a homogenización usando un mezclador u homogenizador correcto, siempre va a existir una heterogeneidad residual.
Tipos de homogeneidad (desde el punto de vista práctico)
En la naturaleza los materiales presentan un híbrido entre estas 5 condiciones.
a) Homogeneidad de tres dimensiones.- Esta es la única forma isotrópica, no degenerada de la homogeneidad de distribución. Es lo que asintóticamente observamos en los homogenizadores.
Una vez que se detienen los homogenizadores comienza actuar la fuerza de gravedad, por lo que esta condición es inestable.
b) Homogeneidad de dos dimensiones.- Esta se produce por la degeneración de una distribución homogénea de 3 dimensiones, por la acción selectiva o diferencial de la gravedad (Caso C).
Existen 2 dimensiones de homogeneidad y 1 dimensión de heterogeneidad.
c) Homogeneidad de una dimensión.- Este tipo de homogeneidad no resulta por causas naturales, sino que es introducida en el proceso por los seres humanos.
Se crea con el fin de alimentar una planta con material que tenga variabilidad uniforme.
Existen 2 dimensiones de heterogeneidad y 1 dimensión de homogeneidad.
La técnica desarrollada para este fin, se aplica en las industrias del cemento y del acero, y se conoce como “bed blending”. Existen varios métodos de bed blending, tales como Chevron, Hileras, Chevcon, etc.
Nota.- Haga clic sobre los nombres de los métodos de bed-blending para ver los videos.
d) Homogeneidad por revolución.- Este tipo de homogeneidad puede definirse como una simetría alrededor de un eje vertical.
Existe 1 dimensión de homogeneidad y 2 dimensiones de heterogeneidad.
Lo observamos en la descarga de material particulado desde una faja transportadora, cuando el material cae en un plano horizontal o en un cilindro cónico alimentado a lo largo de su eje de revolución.
Otro ejemplo donde se usa este tipo de distribución es en el método de cono y cuarteo.
e) Heterogeneidad de tres dimensiones.- Este es el caso más general. Para el Dr. Gy es el estado que siempre deberíamos asumir cuando nada se sabe acerca de la distribución.
Hay 3 dimensiones de heterogeneidad y ninguna distribución de homogeneidad.
Referencia:
[1] Pierre Gy - "Sampling of heterogeneous and dynamic material systems". Ed 1992.
Pincha aquí para saber más acerca de los cursos que se ofrecen para en 2023: CURSOS ONLINE